




在人工智能和视频生成领域,VLOGGER凭借其文本和音频驱动的化身合成技术,实现了从单张图像生成高质量、真实感视频的突破,广泛应用于视频编辑和语言翻译等领域。
VLOGGER的架构
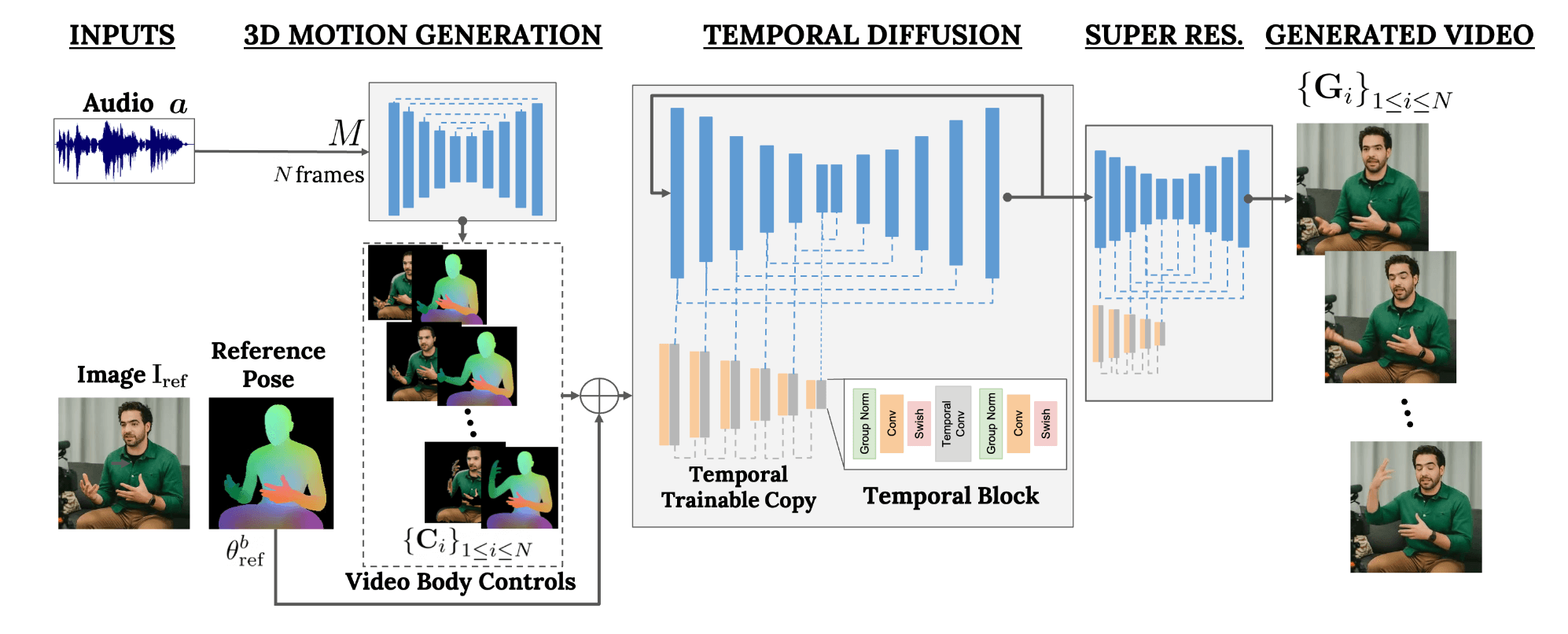
VLOGGER基于两阶段扩散模型管道,提升了人像合成的时空一致性:
-
随机人像到3D动作扩散模型:
- 将音频输入转化为动态肢体运动控制,精确捕捉视线、面部表情和整体姿态。
-
时间图像到图像翻译模型:
- 在传统图像扩散模型中整合预测的身体控制,生成对应帧,保持主体身份和背景一致性。
主要特性和创新
- 多场景处理:适应全身可见和多样身份的场景。
- 身份保留:确保生成视频保留原主体身份。
- 时间一致性:保持帧间视觉和运动一致性。
应用场景
-
视频编辑:
- 调整现有视频中的面部表情或动作,确保无缝编辑。
-
谈话脸生成:
- 从单张图像生成真实的谈话面孔,应用于虚拟助手、教育和娱乐。
-
视频翻译:
- 调整视频以匹配新的音轨,提升语言的可访问性和本地化。
评估与基准
VLOGGER在图像质量、身份保留和生成视频多样性上优于最新技术,并通过大规模的MENTOR数据集验证了其扩展性和鲁棒性。
写到最后
VLOGGER通过多模态扩散模型,实现了高质量、可控的视频生成,拓展了数字内容创作的新可能性。无论是视频内容增强、创建逼真的虚拟化身,还是消除媒体语言障碍,VLOGGER都是一款多功能且强大的工具。


 粤公网安备44030002001270号
粤公网安备44030002001270号