




在当今信息爆炸的时代,视频内容正在迅速成为数据世界的主流。然而,尽管图像和文本的处理技术已经取得了显著突破,视频的分析依旧面临着巨大的挑战,特别是在时空对象的精确理解方面。最近,由阿里巴巴达摩院(DAMO Academy)发布的VideoRefer Suite正是应对这一挑战的创新性解决方案。它通过融合大语言模型(Video LLM),为视频内容分析打开了全新的局面,尤其是在多帧物体识别和时空关系推理方面。
VideoRefer Suite是一个开创性的工具集,它不仅提供了大量高质量的视频数据集,还引入了强大的模型架构,用以提升视频分析中时空对象的理解能力。通过VideoRefer-700K数据集和VideoRefer-Bench评测平台,研究人员可以更精确地进行视频内容的检索、描述生成和问答任务。该技术的亮点在于其精细化的物体级视频理解,使得人工智能能够更好地理解视频中的时空关系,为更广泛的视频分析应用提供支持。
这到底是什么?
VideoRefer是一个基于大语言模型(LLM)的高级视频分析工具集,旨在提供精确的时空物体理解。通过VideoRefer-700K数据集和相应的评测平台,用户能够进行基于视频的任务,如自动生成视频描述、视频中的物体识别及时空关系推理等。其核心亮点在于通过时序数据的深度学习,模型能够识别视频中的动态物体,并通过自然语言生成与视频内容相关的高质量描述。
视频分析的新突破:技术亮点
-
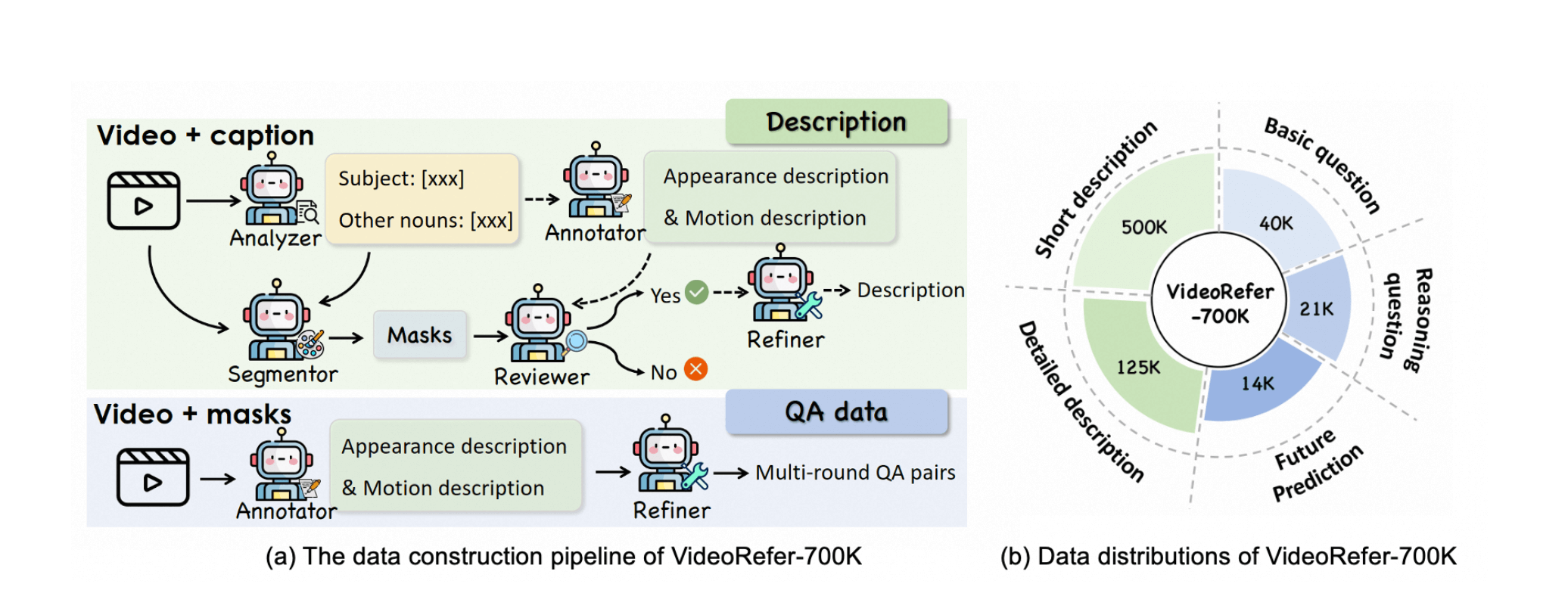
VideoRefer-700K数据集:这个数据集包含了700,000个视频片段,精确标注了不同物体在时空维度上的变化,极大提升了视频分析模型的训练质量。数据集不仅包含静态图片,还结合了每一帧的时空标签,支持复杂的时空推理。
-
VideoRefer模型架构:与传统的视频分析模型不同,VideoRefer模型特别强调视频中的多帧物体识别。它不仅能够识别单一帧中的物体,还能追踪这些物体在不同帧中的演变,进而进行时空理解和推理。这使得其在处理多物体、复杂场景以及动态环境下的视频内容时,展现了显著优势。
-
视频检索与生成描述:通过深度学习技术,VideoRefer模型不仅可以对视频中的物体进行准确定位,还能生成与之相关的自然语言描述。这一功能特别适用于视频内容的搜索引擎、自动摘要和多媒体检索等场景。
-
VideoRefer-Bench评测平台:为了帮助开发者和研究者评估模型的表现,VideoRefer提供了一个全面的评测平台。它支持多种任务类型,如视频描述生成和问题回答(QA),为视频理解领域的研究提供了标准化的评测体系。
市场前景与应用场景
随着短视频平台和直播应用的爆炸式增长,对视频内容的精确分析需求愈加迫切。无论是在内容审核、广告精准投放,还是在智能推荐系统中,VideoRefer都展现了巨大的市场潜力。尤其是其在视频搜索和互动问答中的应用前景,无疑为企业提供了高效的视频内容理解和用户体验提升方案。
在工业界,VideoRefer的技术也能够应用于自动驾驶(通过分析行车视频中的动态物体)、安防监控(通过视频分析识别异常行为)等领域。这种技术的推广,无疑将推动视频AI的全面升级。
背后的技术团队:DAmo团队的卓越领导力
VideoRefer的成功离不开**阿里巴巴达摩院(DAMO Academy)**的强大技术团队。该团队的专家们在计算机视觉、自然语言处理和大数据处理等领域拥有深厚的积淀,推动了该技术的迅速发展。阿里巴巴达摩院在全球AI研究领域的卓越表现,使其能够将VideoRefer打造为行业领先的技术产品。
如何使用VideoRefer?
要使用VideoRefer Suite,用户可以通过其提供的API接口,轻松将模型集成到现有的视频分析系统中。对于开发者来说,VideoRefer的代码和数据集可以通过GitHub访问,且得到了广泛的社区支持。与此同时,VideoRefer还提供了用户友好的界面,帮助非技术人员也能快速实现视频的智能分析。
VideoRefer的Huggingface使用指引
通过Huggingface平台,用户可以直接访问VideoRefer模型,并快速进行部署。Huggingface的强大社区和工具,进一步为开发者提供了便捷的环境来测试和优化模型。
https://huggingface.co/DAMO-NLP-SG/VideoRefer-7B
GitHub页面
VideoRefer的开源代码托管在GitHub上,开发者可以通过访问其GitHub页面,获取更多的技术细节、源代码和社区讨论。
用户评价
从早期的用户反馈来看,VideoRefer的创新技术和高精度的分析能力获得了广泛好评。许多研究人员和开发者表示,VideoRefer在提升视频内容理解的同时,也显著减少了人工标注的时间成本。更为重要的是,该技术在多物体、动态场景下的表现,远超传统的视频分析方法。
数智朋克点评:破局之作
作为一款依托大语言模型技术的视频分析工具,VideoRefer无疑是视频AI领域的一次重大突破。它不仅提升了视频分析的时空理解能力,更通过开源和灵活的应用方式,降低了行业入门门槛,推动了视频内容分析的普及。无论是在科研领域,还是在企业应用中,VideoRefer都具备了巨大的发展潜力。

 粤公网安备44030002001270号
粤公网安备44030002001270号