




在AI发展的浪潮中,视频生成技术逐渐崭露头角。Still-Moving由一支致力于视频生成研究的团队开发,旨在突破传统视频数据的限制,实现定制化的视频生成。团队通过训练轻量级的空间适配器(Spatial Adapters)和运动适配器(Motion Adapter),解决了现有模型中存在的视觉伪影和定制效果不佳的问题。
技术创新
从T2I到T2V的桥梁
现有的文本到图像(T2I)模型,如DreamBooth和StyleDrop,已经展现了惊人的个性化能力。然而,直接将这些模型应用于文本到视频(T2V)模型时,通常会出现显著的视觉伪影或定制效果不佳的问题。为了解决这一问题,仍在运动团队提出了一种创新的方法:通过训练轻量级的空间适配器,调整由T2I层产生的特征。
空间适配器与运动适配器
这种方法的核心在于利用静态视频(即重复的图像)进行训练,这些图像样本来自定制化的T2I模型。通过引入创新的运动适配器模块,团队得以在保持视频模型运动先验的同时,训练这些静态视频。在测试阶段,移除运动适配器模块,仅保留训练好的空间适配器,从而恢复T2V模型的运动先验,同时遵循定制化T2I模型的空间先验。
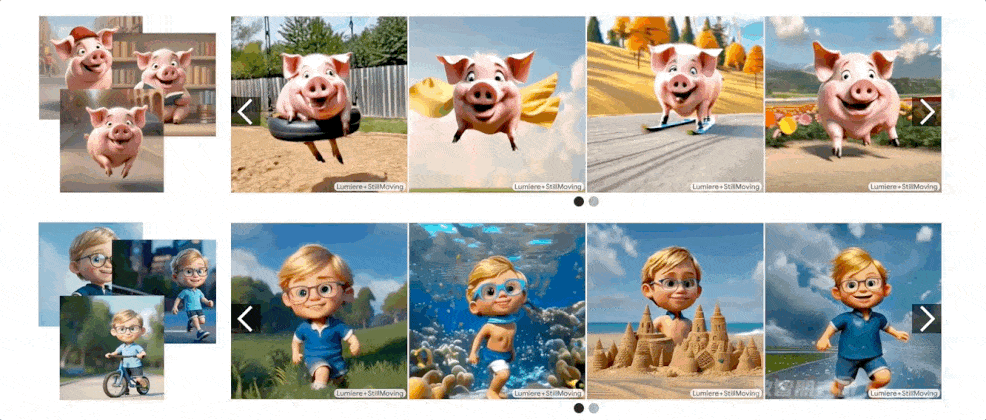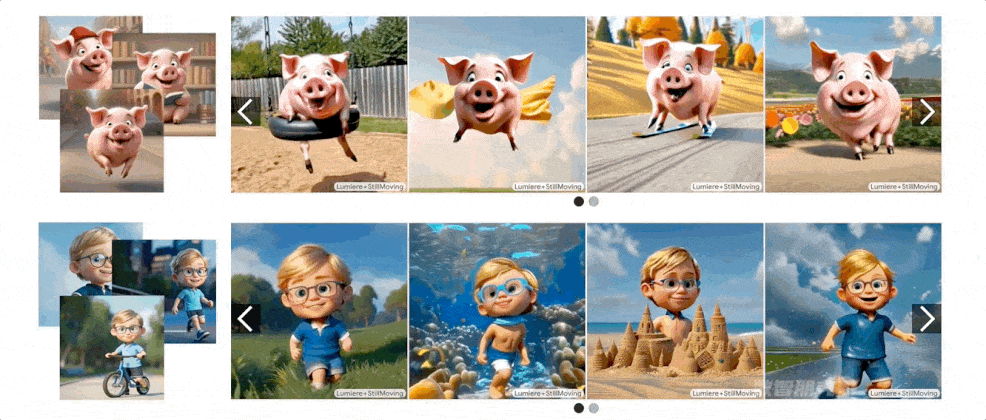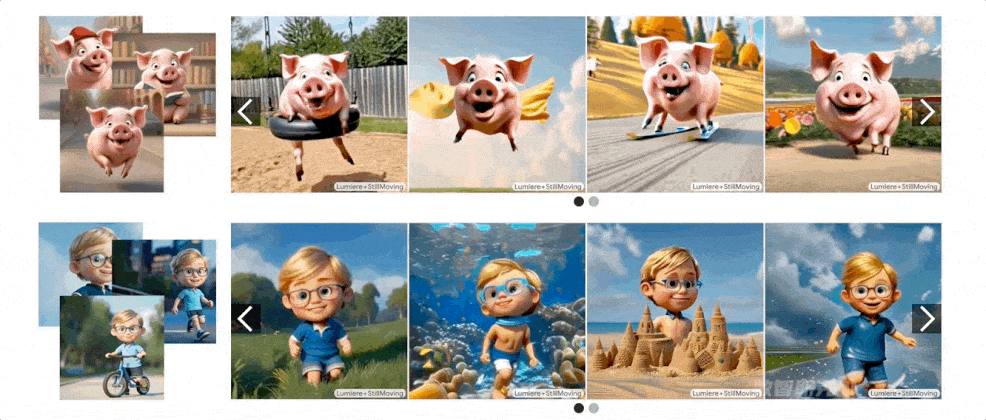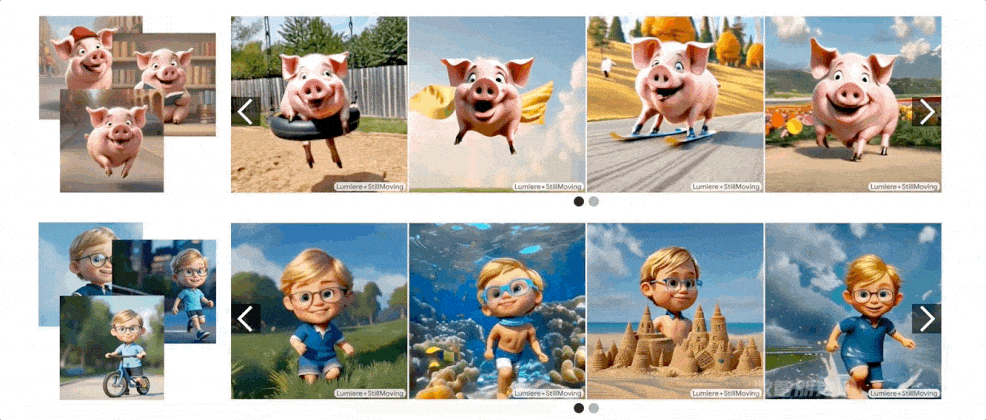
生成示例
个性化视频生成
该方法不仅能生成个性化的视频,还能在保持模型运动先验的同时,展示诸如“披着斗篷飞行的花栗鼠”或“跳进秋叶堆里的猪”等丰富多样的个性化场景 。
风格化视频生成
Still-Moving同样支持风格化视频生成。例如,以风格化的T2I模型(如StyleDrop)为基础,生成一致风格的视频。在这些视频中,风格图像的特征得以完美呈现,同时保留了T2V模型的自然运动。
控制网络与风格化视频生成
通过结合ControlNet,仍在运动能够在保持风格一致的同时,生成结构和动态与参考视频一致的视频。
同类产品对比
在同类技术中,Google推出的Veo模型能够生成1080p分辨率的视频,具有丰富的视觉风格和详细的运动控制能力。模型结合了自然语言和视觉语义的高级理解能力,可以准确地捕捉用户的创意愿景 。此外,Google DeepMind的Transframer技术仅需一张静态图像即可生成30秒的视频,通过分析图像的框架,预测并展示目标从不同角度的样子。OpenAI的Sora模型则利用变换器技术,在处理长序列数据方面表现优异,能够生成具有高度一致性和多样性的视频。
社会影响
尽管该技术的初衷是为用户提供创意和灵活的视觉内容生成工具,但也需警惕其可能被滥用来制作虚假或有害内容。因此,开发和应用工具来检测偏见和恶意使用案例,以确保技术的安全和公平使用,是至关重要的。
数智朋克点评
Still-Moving为个性化和风格化视频生成开辟了新的可能性,通过创新的空间适配器和运动适配器,解决了传统方法中的诸多挑战。这一突破不仅展示了团队的技术实力,也为未来的视频生成应用提供了广阔的前景。在与Google的Veo、DeepMind的Transframer及OpenAI的Sora等领先技术的对比中,仍在运动以其独特的定制化视频生成能力脱颖而出,展示了其在AI视频生成领域的巨大潜力。

 粤公网安备44030002001270号
粤公网安备44030002001270号